
When you’re building an application, you have to map out how your code will travel through the entire software lifecycle—from writing new features to verifying they work correctly before release. Typically, you’re going to need:
- At least one dedicated development environment for new features and bug fixes
- At least one testing environment to run your automated or manual checks
- Beyond those, many teams also add staging or QA environments
The problem with persistent environments

To design these non-prod environments, one (widely-used) option is to set them up as persistent (long-lived) environments. These are persistent setups designed to mimic production as closely as possible. To set them up and keep them running, you would typically need to:
- Provision and maintain dedicated infrastructure. You would first allocate resources for them, such as virtual machines, storage…
- Replicate your app setup. This includes your backend services, middleware, frontend, and supporting components, such as APIs, external integrations, and databases.
- Load seed data into the databases. Empty databases won’t serve you, but you most likely can’t load production data directly into a separate environment (you may have PII, emails…). This means you need to prepare and load seed data, i.e. data that mimics production data but is sanitized to remove sensitive information.
- Set up a system for refreshing seed data across all environments. This ensures the data in your persistent environments stays current with production changes, reflecting the latest schema and new data patterns needed for testing.
- Synchronize configurations. Implement processes to ensure changes made in production (e.g., new environment variables, feature flags, API keys) are consistently applied across all persistent environments.
Setting up environments like this is a tried-and-tested method that works. For example, if you’re building an app on AWS and using a Postgres database in RDS for production, you might provision separate RDS instances for development and testing. These environments would replicate your production configuration, be seeded with sanitized data, and include workflows to keep everything synchronized with production.
But you can probably also see how persistent environments come with a significant amount of overhead. There’s multiple gotchas hidden in this setup:
- Keeping configurations in sync with production (and each other) is easier said than done. Small discrepancies in environment variables, runtime settings, or library versions can lead to bugs that are hard to reproduce and fix. >> Gotcha #1: Configuration drift
- Seed data must be updated across all environments to reflect schema changes or new logic. As you add more environments, this becomes a truly annoying task. >> Gotcha #2: Seed data maintenance
- As you grow your team, persistent environments start being shared among multiple engineers, which can lead to problems—e.g. test data could interfere with multiple feature branches being validated at the same time. >> Gotcha #3: Concurrency issues
- Persistent environments are provisioned 24/7, even when idle. This gets expensive at scale >> Gotcha #4: Growing costs
Persistent environments can work well for smaller teams or projects with predictable workflows, but they can become increasingly painful as your team scales or your product complexity grows.
To adopt a more flexible workflow from the start, you can avoid setting up these non-prod persistent environments at all, and set up ephemeral environments instead.
The idea is to find a way to create temporary, on-demand environments that are discarded automatically when no longer required. Unlike persistent environments, they are not permanently provisioned, and their temporary nature means they come with much less maintenance overhead. They’re more prone to automation and to being directly incorporated into CI/CD pipelines, setting you up for success as your project scales.
How ephemeral environments are typically handled
Ephemeral environments are often built based on automation and lightweight infrastructure to make them easy to create and tear down, for example:
- CI/CD workflows trigger ephemeral environment creation based on certain events, e.g. a pull request being opened. These workflows handle tasks like deploying code, provisioning resources, and connecting the environment to required services
- Docker is used to package the application and its dependencies
- Terraform is used to spin up compute in AWS
- When the task is completed (e.g. PR s merged), CI/CD workflows automatically tear down the environment
But there’s a catch in this system. What happens with the databases that need to populate each environment?
The problem with Postgres databases in ephemeral environments
For ephemeral environments to be useful, they need a fully functional database that mirrors production. For example, if your prod environment runs on Postgres, you’ll need to deploy a Postgres database in your ephemeral environments as well. But databases need data.
This simple problem means you end up carrying over many of the same issues you were trying to eliminate by transitioning from a persistent setup to an ephemeral environment system:
- Seed data takes time to load. Loading even small datasets into a Postgres database takes time, and the larger the dataset, the longer it takes.The rest of your ephemeral environment can spin up in seconds. But if your database takes minutes to load or sync, you’ve sort of negated the speed advantages of ephemeral environments.
- This means limited scalability. When you create multiple ephemeral environments in parallel, like for testing dozens or even hundreds of pull requests simultaneously, this data-loading delay really hurts you.
- You now have to maintain seed data across many environments. On top if it, seed data isn’t static—it evolves alongside your application. Schema changes, new fields, and production updates all require constant updates to your seed files. If you’re creating many ephemeral environments in your new setup, you’ll have to manage seed data across all of them.
A method to deploy Postgres databases in a seconds, with data
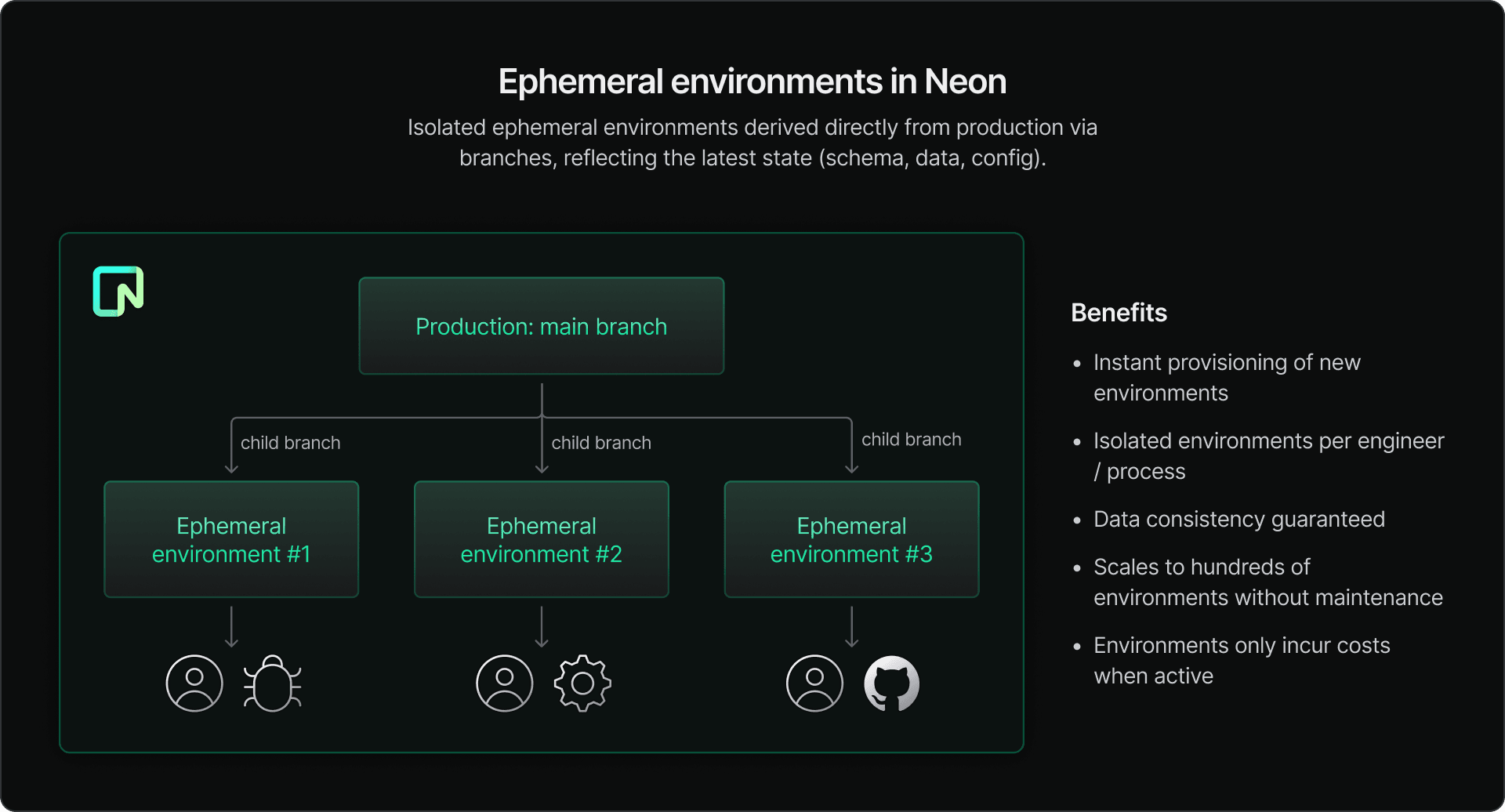
The database often becomes a bottleneck in an otherwise highly agile workflow. One way to address this is by using Neon branches to deploy Postgres in your ephemeral environments.
Neon is a serverless Postgres platform with a free plan that lets you deploy Postgres databases in milliseconds and supports branching. Neon branches are lightweight, copy-on-write clones of your database; instead of duplicating data for every environment, Neon branches reference the same underlying storage as the parent database, which acts as the source of truth. This allows you to spin up fully functional database “clones” almost instantly, which is great for ephemeral environments.
- Copy-on-write magic. When you create a Neon branch, it doesn’t copy all the data upfront. Instead, it references the same data pages as the parent database.
- Ready instantly. Because Neon branches don’t require a full copy of the database, they can be created in seconds, even for large datasets (dataset size has no effect actually).
- Ephemeral by design. Branches are temporary and can be deleted automatically when no longer needed (you can set this up via CI/CD automations and APIs).
- One-click reset. If you need to refresh your test environment, it can be reset to match the parent database state instantly—it just takes one API call.
Instead of deploying Postgres directly into your containers, you can use Neon branches as your Postgres database. Each branch has its own unique URL, and everything can be managed through the Neon API. This way, each database you create already includes your testing data, drastically reducing the effort required to maintain data consistency.
Example workflow
Data loading to the main branch (source of truth)
First, you populate a main branch (e.g., main_dev) in Neon with your testing dataset. This main branch acts as the single source of truth for all ephemeral environments, allowing you to maintain consistency in one centralized location.
Child branch creation (ephemeral environments)
When a developer opens a PR, GitHub Actions triggers the creation of an ephemeral environment. The setup includes creating a child branch from the Neon main branch and spinning up the app’s backend, frontend, and other services. The child branch is the Postgres URL for the ephemeral environment.
Development and testing
Once the ephemeral environment is ready, engineers in your team can:
- Work in isolation. All changes are confined to the branch associated with this particular environment. The parent and other environments are unaffected.
- Keep data consistency. Neon branches are instantly populated with the same dataset as the parent.
- Iterate quickly. If the environment needs a refresh during testing, the branch can be reset instantly to match the parent branch’s current state using Neon’s Reset from Parent feature.
- Keep it affordable. Neon’s scale-to-zero ensures that inactive branches consume no resources, reducing costs even if cleanup workflows are delayed.
Discarding the environment
When the PR is merged, GitHub Actions triggers the deletion of the environment, including its database branch.
Explore our documentation for detailed guides on how to implement this workflow.
Use cases to get started
By integrating Neon branches into your ephemeral environments, you’re solving the last major hurdle holding your speed down—databases.
You can try it for multiple use cases:
Neon’s Free Plan gives you 10 independent projects with up to 10 branches per project at no cost. Give it a go let us know how it went on Discord. For larger teams, Neon’s Scale Plan ($69/month) will give you thousands of branches at no additional cost, more than enough to cover all your non-prod environments.



